 Donate
Donate
 Donate
Donate
Improved Training of Wasserstein GANs
Add an identifier
Thank You!
Abstract: Generative Adversarial Networks (GANs) are powerful generative models, but
suffer from training instability. The recently proposed Wasserstein GAN (WGAN)
makes progress toward stable training of GANs, but sometimes can still generate
only low-quality samples or fail to converge. We find that these problems are
often due to the use of weight clipping in WGAN to enforce a Lipschitz
constraint on the critic, which can lead to undesired behavior. We propose an
alternative to clipping weights: penalize the n ...
2
Entering edit mode

4.2 years ago
Andy
146
In Appendix F, the authors say "The generator and critic are residual networks; we use pre-activation residual blocks with two 3 × 3 convolutional layers each and ReLU nonlinearity."
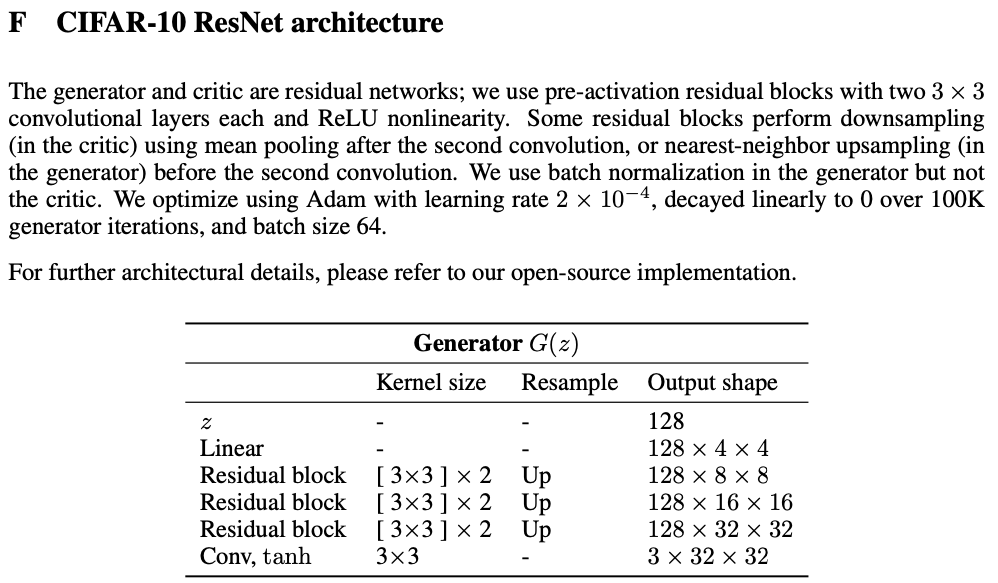
Based on this, I'm thinking something like
def resblock(x, training=False):
y = conv1(x)
y = bn1(x, training=training)
y = relu(x)
y = conv2(x)
y = bn2(x, training=training)
return relu(y + matmul(W, x))
where W is some trainable weight matrix sized correctly to account for whatever padding is being used in the conv layers. I'm not really sure what's meant by "pre-activation residual blocks" though and generally, I'm not sure if I've got the implementation quite right.
This is also related to the paper arXiv:1802.05957
Similar Posts
Loading Similar Posts
Traffic: 2 users visited in the last hour